
Tomcat Clustering
Clustering refers to running multiple instances of Tomcat that appear as one Tomcat instance. If one instance was to fail the other instances would take over thus the end user would not notice any failures.
Clustering in Tomcat enables a set of Tomcat instances on a LAN to appear to the users a single server, as detailed in the below picture. This architecture allows more requests to handled and can handle if one server were to crash (High Availability) .
Incoming requests are distributed across all servers, thus the service can handle more users. This approach is known as horizontal scaling thus you can buy cheaper hardware and still use existing hardware without having to upgrade your existing hardware.
There are a number of different clustering models that are used Master-Backup, Fail-Over, Tomcat uses both of these and incorporates load balancing as well.
Tomcat Clustering Model
The Tomcat clustering model can be divided into two layers and various components
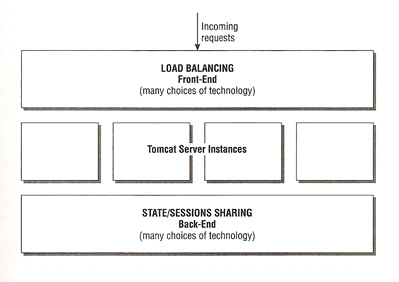
The two layers that enable clustering are the load-balancing frontend and the state-sharing/synchronization backend. The front-end deals with incoming requests and balancing them over a number of instances, while the backend is concerned with ensuring that shared session data is available to different instances.
There are a number of load-balancing frontends that you can use
Depending on your budget, most setups either use hardware-based load-balancer or Apache mod_proxy/mod_jk. I have already touched on how to configure a Apache mod_proxy and mod_jk in the Apache Server selection. The area I did not cover was the use of Sticky Sessions or Session Affinity, what this means when set is that incoming requests with the same session are routed to the same Tomcat worker.
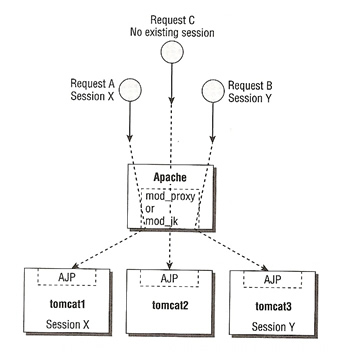
They only problem with sticky sessions is that if a Tomcat instance were to fail then all sessions are lost, but as with the load-balancing frontend, you have numerous session-sharing backends from which to choose. Each provides a different level of functionality as well as implementation complexity.
mod_proxy and mod_jk offer the following options
Sticky Session with no clustered session sharing ensures that that requests are handled by the same instance, the session ID is encoded with the route name of the server instance that created it, assisting in the routing of the request. This solution can be used by most Production system, it is simple and easy to maintain, there is no additional configuration or resource overhead but this solution has no HA capability, thus if a server were to crash all session data is lost with it.
Sticky Session with a persistence manager and a shared file store, which is already built into Tomcat. The idea is to stored session data thus in the event of a failure the session data can be retrieved. Using a shared disk device (NFS, SMB) all the Tomcat instances has access to the session data. However Tomcat will not guarantee when a sessions data will be persisted to the file store, thus you could have a case where a Tomcat instance crashes but the session data was not written to the file store. It only offers a slightly better solution to the one above.
Sticky session with a persistence session manager and a JDBC-based store, is the same as the file-based store, but uses a RDMBS instead
In-memory session replication, is session data replicated across all Tomcat instances within the cluster, Tomcat offers two solutions, replication across all instances within the cluster or replication to only its backup server, this solution offers a guaranteed session data replication, however this solution is more complex.
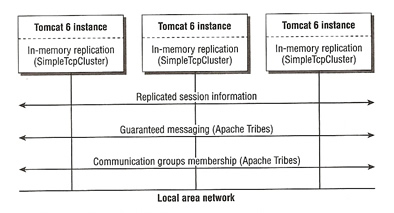
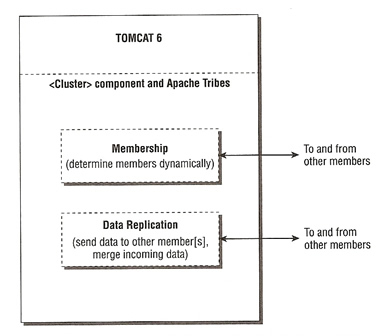
The Tomcat server instances running in the cluster are implemented as a communications group. At the Tomcat instance level, the cluster implementation is an instance of the SimpleTcpCluster class. Depending on your needs and the replication pattern, you can configure SimpleTcpCluster with one or two managers
SimpleTcpCluster uses Apache Tribes to maintain communicate with the communications group. Group membership is established and maintained by Apache Tribes, it handles server crashes and recovery. Apache Tribes also offer several levels of guaranteed message delivery between group members. This is achieved updating in-session memory to reflect any session data changes, the replication is done immediately between members. This solution offers full HA but at a cost to heavy network loads, also additional hardware is often required to make sure there are no single points of failure in the network.
Sessions are objects (which can contain and reference to other objects) that are kept on behalf of the a client. Because HTTP is stateless there is no simple way to maintain application state using the protocol alone. A server-side session is the main mechanism used to maintain state, it works as follows
If a browser does not support cookies, it is possible to use URL rewrite to achieve a similar effect, the URL is decorated with the session ID being used.
Setting up Multiple Instances on one Machine
The cluster consists of three independent Tomcat instances and uses the following, the following is the setup used by all three Session-Sharing methods which i will go into detail later, but first the front-end
In the real world you would setup each instance on a separate server, but in this case each instance must have the following
Three batch files called start1.bat, start2.bat and start3.bat are created and placed in the Tomcat bin directory. Each of the files set the CATALINA_HOME environment variable and then call the startup.bat file, so in each of the startup set the CATALINA_HOME variable to point to each instance
| startup file | # startup1.bat set CATALINA_HOME=c:\cluster\machine1 call startup |
| shutdown file | # stop1.bat set CATALINA_HOME=c:\cluster\machine1 call shutdown |
We will use the minimal configuration just to get the cluster up and running, so copy the directory structure below from a clean installation of Tomcat
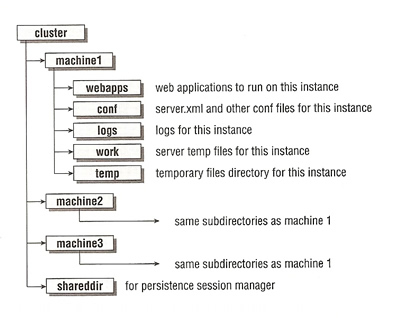
First you must disable the HTTP connector, then change the AJP Connector and shutdown port for each of the instances
| Instance Name | File to Modify | TCP Ports (Shutdown, AJP Connector) |
| machine 1 | \cluster\machine1\conf\server.xml | 8005, 8009 |
| machine 2 | \cluster\machine2\conf\server.xml | 8105, 8109 |
| machine 3 | \cluster\machine3\conf\server.xml | 8205, 8209 |
If you still have a problems starting the Tomcat instance due to port binding use the "netstat" command to find what is using the above port or to look for free ports.
Next you need to set a unique jvmRoute for each instance, i have already discussed jvmRoute
| jvmRoute | <Engine name="Catalina" defaultHost="localhost" jvmRoute="machine1"> Note: the other instances will be machine2 and machine3 |
To indicate to a Servlet Container that the application can be clustered, a Servlet 2.4 standard <distributable/> element is placed into the applications deployment descriptor (web.xml). If this element is not added, the session maintained by this application across the three Tomcat instances will not be shared. You can also add it to the Context element
| distributable | <Context distributable="true" /> |
The front-end is setup in the Apache Server, i am not going to go into to much detail as i have already covered load-balancing
| workers.properties file | worker.list = loadbal1,stat1 worker.machine1.type = ajp13 worker.machine1.host =192.168.0.1 worker.machine1.port = 8009 worker.machine1.lbfactor = 10 worker.machine2.type = ajp13 worker.machine2.host =192.168.0.2 worker.machine2.port = 8109 worker.machine2.lbfactor = 10 worker.machine3.type = ajp13 worker.machine3.host =192.168.0.3 worker.machine3.port = 8209 worker.machine3.lbfactor = 10 worker.bal1.type = lb worker.bal1.sticky_session = 1 worker.bal1.balance_workers = machine1, machine2, machine3 worker.stat1.type= status |
| httpd.conf updates | JkMount /examples/jsp/* bal1 JkMount /jkstatus/ stat1 JkWorkersFile conf/workers.properties |
| JSP page | # Create file sestest.jsp <%@page language="java" %> Note: create for each instance and change the machine name above |
The above is the same setup for all three Session-Sharing backends, which I am now going to show you how to set these up.
The first i am going to setup is the In-Memory replication, two components needs to be configured to enable in-memory configuration, the <Cluster> element is responsible for the actual session replication, this includes the sending of new session information to the group, incorporating new incoming session information locally and management of group membership (it uses Apache Tribes). The other component is a replication Valve which is used to reduce the potential session replication traffic by ruling out (filtering) certain requests from session replication.
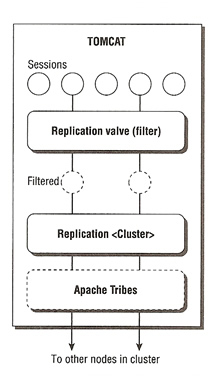
The only implementation of in-memory replication is called SimpleTcpCluster, it uses Apache Tribes for communication which uses regular multicasts (heartbeat packets) to determine membership. All node that are running must multicasts a heartbeat at regular frequency, if they do not send a heartbeat the node is considered dead and is removed from the cluster. The membership of the cluster is managed dynamically as nodes are added or removed. Session data is replicated between the all nodes in the cluster via TCP by using end-to-end communication.
Because of the amount of network traffic generated, you should only use a small number of nodes within the cluster, unless you have vast amounts of memory and can supply a high bandwidth network. You can reduce the amount of data by using the BackupManager (send only to one node, the backup node) instead of DeltaManager (sends to all nodes within the cluster).
| Element | Description |
| <Cluster> | The cluster element is nested inside an enclosing <Host> element, it essentially enables session replication for all applications in the host. |
| <Manager> | This is a mandatory component, this is where you configure either DeltaManager or BackupManager, they both send replication information to others via Channels from the Apache Tribes group communications library. |
| <Channel> | A channel is an abstract endpoint, (like a socket) that a member of the group can send and receive replicated information through. Channels are managed and implemented by the Apache Tribes communications framework. Channel has only one attribute. |
| <Membership> | This attribute selects the physical network interface to use on the server (if you have only one network adapter you generally don't need this). This service is based on sending a multicasts heartbeat regularly, which determines and maintains information on the servers that are considered part of the group (cluster) at any point in time. |
| <Receiver> | This element configures the TCP receiver component of the Apache Tribes Framework, it receives the replicated data information from other members. |
| <Sender> |
This element configures the TCP sender component of the Apache Tribes Framework, it sends the replicated data information to other members. |
| <Transport> | This element performs the real stuff, tribes support having a pool of senders, so that messages can be sent in parallel and if using NIO sender, you can send messages concurrently as well. |
| <Interceptor> | Interceptor components are nested components of <Channel> and are message processing components that can chained together to alter the behavior or add value to the option of a channel. basically you have a option flag that will trigger its operation. |
| <Valve> | This element acts as a filter for In-Memory replication, it reduces the actual session replication network traffic by determining if the current session needs to be replicated at the end of the request cycle. Even through this element is inside the <Cluster> element it is consider to be inside the <Host> element. |
| <ClusterListener> | Some of the work of the cluster is performed by hooking up listeners to replication messages that are passing through it. You must configure org.apache.catalina.ha.session.JvmRouteSessionIDBinderListener if you are using JvmRouteBinderValve to ensure session stickiness transfers with a fail-over |
Now to go into details on what options each element can have
<Cluster> Element |
||
| Attribute Name | Description |
default |
| className | The implementation Java Class for the cluster manager current uses org.apache.catalina.ha.tcp.SimpleTcpCluster |
|
| channelSendOptions | Option flags are included with messages sent and can be used to trigger Apache Tribes channel interceptors. The numerical value is a logical OR flag values including Channel.SEND_OPTIONS_ASYNCHRONRONUS 8 Channel.SEND_OPTIONS_BYTE_MESSAGE 1 Channel.SEND_OPTIONS_SECURE 16 Channel.SEND_OPTIONS_SYNCHRONIZED_ACK 4 Channel.SEND_OPTIONS_USE_ACK 2 |
11 (async with ack) |
<Manager> Element (mandatory) |
||
| Attribute Name | Description |
default |
| className | org.apache.catalina.ha.session.DeltaManager org.apache.catalina.ha.session.BackupManager |
|
| name | A name for the cluster manager, this name should be the same on all instances | |
| notifyListeners-OnReplication | Indicates if any session listeners should be notified when sessions are replicated between instances | false |
| expireSessions-OnShutdown | Specifies whether it is necessary to expire of all sessions upon application shutdown | false |
| domainReplication | Specifies whether replication should be limited to domain members only, this option is only available for DeltaManager | false |
| mapSendOptions | When using the BackupManager, this maps the send options that are set to trigger interceptors | 8 (async) |
<Channel> Element |
||
| Attribute Name | Description |
default |
| className | org.apache.catalina.tribes.group.GroupChannel | |
<Membership> Element |
||
| Attribute Name | Description |
default |
| className | org.apache.catalina.tribes.membership.McastService | |
| address | The multicast address selected for this instance | 228.0.0.4 |
| port | The multicast port used | 45564 |
| frequency (milliseconds) | Frequency which heartbeat multicasts are sent (in milliseconds) | 500 |
| dropTime (milliseconds) | The time elapsed without heartbeats before the service considers a member has died and removes it from the group (in milliseconds) | 3000 |
| ttl | Sets the time-to-live for multicast messages sent (may be used if network traffic are going through any routers) | |
| soTimeout | The SO_TIMEOUT value on the socket that multicasts messages are sent to. Controls the maximum time to wait for a send/receive to complete | 0 |
| domain | For partitioning group members into separate domains for replication. | |
| bind | The IP address of the adaptor that the service should bind to. | 0.0.0.0 |
<Receiver> Element |
||
| Attribute Name | Description |
default |
| className | org.apache.catalina.tribes.transport.nio.NioReceiver | |
| address | The IP address to bind to, to receive incoming TCP data (you must sent this for multi-homed hosts) | auto |
| port | Selects the port to use for imcoming TCP data. | 4000 |
| autoBind | Tells the framework to hunt for an available port, starting for the specified port number <port> and add up to this number | 1000 |
| selectorTimeout (millseconds) | Bypass for old NIO bug. sets the milliseconds timeout while polling for incoming messages | 5000 |
| maxThreads | The maximum number of threads to create to receive incoming messages | 6 |
| minThreads | The minimum number of threads to create to receive incoming messages | 6 |
<Sender> Element (must contain a Transmitter element) |
||
| Attribute Name | Description |
default |
| className | org.apache.catalina.tribes.transport.ReplicationTransmitter | |
<Transmitter> Element |
||
| Attribute Name | Description |
default |
| className | org.apache.catalina.tribes.transport.nio.PooledParallelSender org.apache.catalina.tribes.transport.bio.PooledMultiSender |
|
| maxRetryAttempts | The number of retries the framework conducts when encountering socket-level errors during sending of a message | 1 |
| timeout | The SO_TIMEOUT value on the socket that messages are sent on. Controls the maximum time to wait for a send to complete | 3000 |
| poolsize | Controls the maximum number of TCP connections opened by the sender between the current and another member in the group. only available when using org.apache.catalina.tribes.transport.nio.PooledParallelSender | 25 |
<Interceptor> Element |
||
| Attribute Name | Description |
|
| org.apache.catalina.tribes.group.interceptors .TcpFailureDetector |
When membership pings do not arrive the interceptor attempts to connect to the problematic member to validate that the member is no longer reachable before the membership list is adjusted | |
| org.apache.catalina.tribes.group.interceptors .MessageDispatch5Interceptor |
The asynchronous message dispatcher, triggered by default send option value 8 (its hard coded) | |
| org.apache.catalina.tribes.group.interceptors .ThroughputInterceptor |
Logs cluster messages throughput information to Tomcat logs | |
Replication <Valve> Element |
||
| Attribute Name | Description
|
|
| className | org.apache.catalina.ha.tcp.ReplicationValve | |
| filter | A semicolon-delimited list of URL pattern for requests that are to be filtered out. | |
Example |
||
| server.xml file | <Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster" channelSendOptions="8"> <Manager className="org.apache.catalina.ha.session.DeltaManager" <Membership className="org.apache.catalina.tribes.membership.McastService" <Receiver className="org.apache.catalina.tribes.transport.nio.NioReceiver" <Sender className="org.apache.catalina.tribes.transport.ReplicationTransmitter"> <Interceptor className="org.apache.catalina.tribes.group.interceptors.TcpFailureDetector"/> <Interceptor className="org.apache.catalina.tribes.group.interceptors.MessageDispatch15Interceptor"/> <Valve className="org.apache.catalina.ha.tcp.ReplicationValve" <ClusterListener className="org.apache.catalina.ha.session.JvmRouteSessionIDBinderListener"/> Note: the port in bold is the one you need to change for each instance |
|
Testing In-Memory Session Replication Cluster
You need to perform the following to test the In-Memory session replication
I have a catalina log file with cluster logging information, starting up, a node going down and rejoining, this log file is from the example I have given above, although I used different IP address but i am sure you get the idea.
Persistent Session Manager with a shared file store
To setup a persistent session manager you must comment out the <Cluster> element in each instance, this disables the In-Memory replication mechanism, then add a context.xml file to each instance with the below
| context.xml | <Context <Manager className="org.apache.catalina.session.PersistentManager" > <Store className="org.apache.catalina.session.FileStore" directory="c:\\cluster\shareddir" /> </Manager> </Context> |
Persistent Session Manager with a JDBC store
The only difference between a file-based store and a JDBC-based store is the <store> element
| context.xml | <Store className="org.apache.catalina.session.JDBCStore" connectionURL="jdbc:mysql://localhost/datadisk?user=tomcat&password=tomcat" driverName="com.mysql.jdbc.Driver" sessionIdCol="session_id" sessionValidCol="valid_session" sessionMaxInactiveCol="max_inactive" sessionLastAccessCol="last_access" sessionTable="tomcat_sessions" sessionAppCol="app_context" sessionDataCol="session_data" /> |
| Create a table in your database | create table tomcat_sessions ( session_id varchar(100) not null primay key, valid_session char(1) not null, max_inactive int not null, last_access bigint not null, app_context varchar(255), session_data meduimlob, KEY kapp_context(app_context) ); |