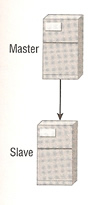
Replication
Replication allows you to keep database servers synchronized, be it that the servers are in the same data center or across different locations. MySQL uses the terminology master server and slave server to represent the two servers that are involved in replication. Replication could be used for the following reasons
A slave can only have one master, but a master can have many slaves, but you can have a master be a slave to another master, don't worry too much I will discuss later on how you can configure a number of different configurations.
When you are talking about replication be is database, disk storage, etc you will come across two terms
| synchronous (mysql uses semi-synchronous) |
means that the data has to be committed on slave (or mirrored, replicated, etc) server before the master server can continue, the master server will wait for an acknowledgment from the slave or a timeout occurs, this could cause a delay depending on the underlying infrastructure and the location of the slave server. |
| asynchronous | means that the does not have to wait for the data to be committed on the salve server before the master server can continue. The master simply write the changes to the binary log with no regard to the status of the salve servers. This means there is no guarantee that replication is actually synchronized the data, however it is faster than synchronous. |
MySQL replication uses asynchronous, however it is possible to use semi-synchronous mode using a plugin here is a link on how to set this up http://dev.mysql.com/doc/refman/5.6/en/replication-semisync-installation.html.
When replication is setup data is written to the binary log, any slave servers connected to the master server uses what is called an I/O thread process which writes the statements or data received from the master server into the relay log, the SQL thread is the process that reads the from the relay log and then replays the statements or data changes for the MySQL process on the slave server. The end result is that the slave server has actually run the same statements as the master server executed. If the slave server is also configured as a master server of other slaves, it simply writes its own binary logs and the secondary salves read from that binlog using their own I/O threads.
Firstly I will start off with a simple replication consisting of one master and one slave, which generally the most popular, the setup is very easy and consists of making a few changes to the MySQL configuration file
To set a simple master slave configuration see below
Master Server (setup) |
Slave Server (setup) |
|
| changes to the configuration file (simple master-slave) |
## In the [mysqld] directive add the following ## now restart MySQL ## Now create a replication user, replace the <host> with the hostname of the slave |
## In the [mysqld] directive add the following ## now restart MySQL ## If the master server has data ## if the master has data you need to get the slave server identical, see backups ## If the master server has no data ## if your master server information was not stored in the backup or if you |
Now that you know how to setup a simple master, slave configuration, you can setup more complex configurations using the same as above
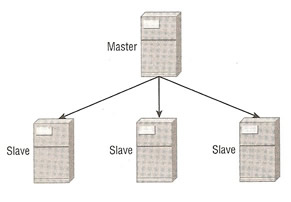
| single master with multiple slaves | ## this setup is the same as the master-slave above, you need to make sure that you change the server-id for each slave [mysqld] |
 |
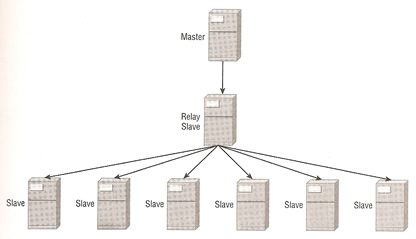
| master and relay slave | ## this option the relay slave will have to have the configuration below in the [mysqld] [mysqld] server-id = X log-bin = mysql-bin log-slave-updates |
 |
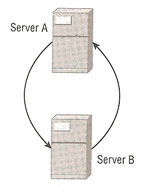
| master-master | ## with a master-master configuration, the primary issue is that both servers could potentially be simultaneously inserting ## only add to Server A |
 |
| circular replication | ## This also known as multi-master replication, again you will need auto_increment settings and the relay slave setting [mysqld] server-id = X log-bin = mysql-bin log-slave-updates ## only add to Server A auto_increment_increment = 10 auto_increment_offset = 1 ## only add to Server B auto_increment_increment = 10 auto_increment_offset = 2 ## only add to Server B auto_increment_increment = 10 auto_increment_offset = 3 ## only add to Server D auto_increment_increment = 10 auto_increment_offset = 4 |
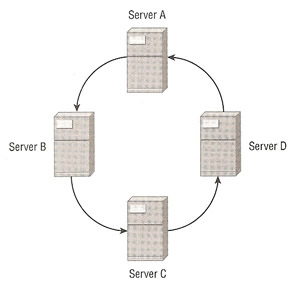 |
One thing when creating complex configurations is the issues you get when part of the network goes down, you may get problems where one server cannot write changes to another server, this means that servers can become out of sync with other servers, make sure that you test this situation and have the documentation ready on how to recover from these problems, personally I have only used the simple master to slave and master to multiple slave configurations.
There are times when the data set on the master and the slave differ this is known as data drift, this can occur if you are using non-deterministic functions or allowing write access to a slave server, you can download the Maatkit tool kit which can help resolve these issues, the tools are all written in Perl and can help in the following