Before Remastering
After Remastering
RAC Backups and Recovery
Backups and recovery is very similar to a single instance database. This article covers only the specific issues that surround RAC backups and recovery, I have already written a article on standard Oracle backups and recovery.
Backups can be different depending on the the size of the company
Oracle RAC can use all the above backup technologies, but Oracle prefers you to use RMAN oracle own backup solution.
Oracle backups can be taken hot or cold, a backup will comprise of the following
Databases have now grown to very large sizes well over a terabyte in size in some cases, thus tapes backups are not used in these cases but sophisticated disk mirroring have taken their place. RMAN can be used in either a tape or disk solution, it can even work with third-party solutions such as Veritas Netbackup.
In a Oracle RAC environment it is critical to make sure that all archive redolog files are located on shared storage, this is required when trying to recover the database, as you need access to all archive redologs. RMAN can use parallelism when recovering, the node that performs the recovery must have access to all archived redologs, however, during recovery only one node applies the archived logs as in a standard single instance configuration.
Oracle RAC also supports Oracle Data Guard, thus you can have a primary database configured as a RAC and a standby database also configured as a RAC.
In a RAC environment there are two types of recovery
Redo information generated by an instance is called a thread of redo. All log files for that instance belong to this thread, an online redolog file belongs to a group and the group belongs to a thread. Details about log group file and thread association details are stored in the control file. RAC databases have multiple threads of redo, each instance has one active thread, the threads are parallel timelines and together form a stream. A stream consists of all the threads of redo information ever recorded, the streams form the timeline of changes performed to the database.
Oracle records the changes made to a database, these are called change vectors. Each vector is a description of a single change, usually a single block. A redo record contains one or more change vectors and is located by its Redo Byte Address (RBA) and points to a specific location in the redolog file (or thread). It will consist of three components
Checkpoints are the same in a RAC environment and a single instance environment, I have already discussed checkpoints, when a checkpoint needs to be triggered, Oracle will look for the thread checkpoint that has the lowest checkpoint SCN, all blocks in memory that contain changes made prior to this SCN across all instances must be written out to disk. I have discussed how to control recovery in my Oracle section and this applies to RAC as well.
Crash recovery is basically the same for a single instance and a RAC environment, I have a complete recovery section in my Oracle section, here is a note detailing the difference
For a single instance the following is the recovery process
For a RAC instance the following is the recovery process
Oracle RAC uses a two-pass recovery, because a data block could have been modified in any of the instances (dead or alive), so it needs to obtain the latest version of the dirty block and it uses PI (Past Image) and Block Written Record (BWR) to archive this in a quick and timely fashion.
| Block Written Record (BRW) | The cache aging and incremental checkpoint system would write a number of blocks to disk, when the DBWR completes a data block write operation, it also adds a redo record that states the block has been written (data block address and SCN). DBWn can write block written records (BWRs) in batches, though in a lazy fashion. In RAC a BWR is written when an instance writes a block covered by a global resource or when it is told that its past image (PI) buffer it is holding is no longer necessary. |
| Past Image (PI) | This is was makes RAC cache fusion work, it eliminates the write/write contention problem that existed in the OPS database. A PI is a copy of a globally dirty block and is maintained in the database buffer cache, it can be created and saved when a dirty block is shipped across to another instance after setting the resource role to global. The GCS is responsible for informing an instance that its PI is no longer needed after another instance writes a newer (current) version of the same block. PI's are discarded when GCS posts all the holding instances that a new and consistent version of that particular block is now on disk. I go into more details about PI's in my cache fusion section. |
The first pass does not perform the actual recovery but merges and reads redo threads to create a hash table of the blocks that need recovery and that are not known to have been written back to the datafiles. The checkpoint SCN is need as a starting point for the recovery, all modified blocks are added to the recovery set (a organized hash table). A block will not be recovered if its BWR version is greater than the latest PI in any of the buffer caches.
The second pass SMON rereads the merged redo stream (by SCN) from all threads needing recovery, the redolog entries are then compared against a recovery set built in the first pass and any matches are applied to the in-memory buffers as in a single pass recovery. The buffer cache is flushed and the checkpoint SCN for each thread is updated upon successful completion.
I have a detailed section on cache fusion, this section covers the recovery, cache fusion is only used in RAC environments, as additional steps are required, such as GRD reconfiguration, internode communication, etc. There are two types of recovery
In both cases the threads from failed instances need to be merged, in a instance recovery SMON will perform the recovery where as in a crash recovery a foreground process performs the recovery.
The main features (advantages) of cache fusion recovery are
In cache fusion the starting point for recovery of a block is its most current PI version, this could be located on any of the surviving instances and multiple PI blocks of a particular buffer can exist.
Remastering is the term used that describes the operation whereby a node attempting recovery tries to own or master the resource(s) that were once mastered by another instance prior to the failure. When one instance leaves the cluster, the GRD of that instance needs to be redistributed to the surviving nodes. RAC uses an algorithm called lazy remastering to remaster only a minimal number of resources during a reconfiguration. The entire Parallel Cache Management (PCM) lock space remains invalid while the DLM and SMON complete the below steps
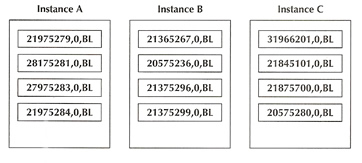
Lets look at an example on what happens during a remastering, lets presume the following
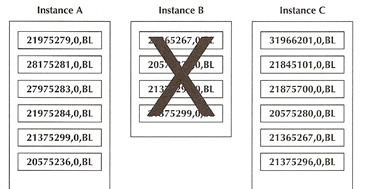
Instance B is removed from the cluster, only the resources from instance B are evenly remastered across the surviving nodes (no resources on instances A and C are affected), this reduces the amount of work the RAC has to perform, likewise when a instance joins a cluster only minimum amount of resources are remastered to the new instance.
Before Remastering |
After Remastering |
|
|
You can control the remastering process with a number of parameters
| _gcs_fast_config | enables fast reconfiguration for gcs locks (true|false) |
| _lm_master_weight | controls which instance will hold or (re)master more resources than others |
| _gcs_resources | controls the number of resources an instance will master at a time |
you can also force a dynamic remastering (DRM) of an object using oradebug
| force dynamic remastering (DRM) | ## Obtain the OBJECT_ID form the below table ## Determine who masters it |
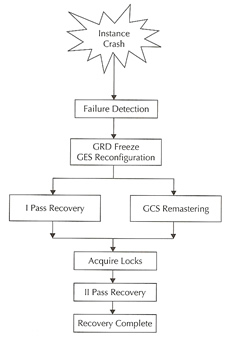
The steps of a GRD reconfiguration is as follows
Graphically it looks like below
| Previous | Menu | Next |