Global Resource Directory (GRD)
The RAC environment includes many resources such as multiple versions of data block buffers in buffer caches in different modes, Oracle uses locking and queuing mechanisms to coordinate lock resources, data and interinstance data requests. Resources such as data blocks and locks must be synchronized between nodes as nodes within a cluster acquire and release ownership of them. The synchronization provided by the Global Resource Directory (GRD) maintains a cluster wide concurrency of the resources and in turn ensures the integrity of the shared data. Synchronization is also required for buffer cache management as it is divided into multiple caches, and each instance is responsible for managing its own local version of the buffer cache. Copies of data are exchanged between nodes, this sometimes is referred to as the global cache but in reality each nodes buffer cache is separate and copies of blocks are exchanged through traditional distributed locking mechanism.
Global Cache Services (GCS) maintain the cache coherency across buffer cache resources and Global Enqueue Services (GES) controls the resource management across the clusters non-buffer cache resources.
Cache coherency identifies the most up-to-date copy of a resource, also called the master copy, it uses a mechanism by which multiple copies of an object are keep consistent between Oracle instances. Parallel Cache Management (PCM) ensures that the master copy of a data block is stored in one buffer cache and consistent copies of the data block are stored in other buffer caches, the process LCKx is responsible for this task.
The lock and resource structures for instance locks reside in the GRD (also called the DLM), its a dedicated area within the shared pool. Details about the data blocks resources and cached versions are maintained by GCS. Additional details such as the location of the most current version, state of the buffer, role of the data block (local or global) and ownership are maintained by GES. Global cache together with GES form the GRD. Each instance maintains a part of the GRD in its SGA. The GCS and GES nominate one instance, this will become the resource master, to manage all information about a particular resource. Each instance knows which instance master is with which resource.
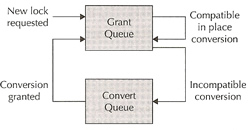
A resource is an identifiable entity, it has a name or reference. The referenced entity is usually a memory region, a disk file, a data block or an abstract entity. A resource can be owned or locked in various states (exclusive or shared), all resources are lockable. A global resource is visible throughout the cluster, thus a local resource can only be used by the instance at it is local too. Each resource can have a list of locks called the grant queue, that are currently granted to users. A convert queue is a queue of locks that are waiting to be converted to particular mode, this is the process of changing a lock from one mode to another, even a NULL is a lock. A resource has a lock value block (LVB). The Global Resource Manager (GRM) keeps the lock information valid and correct across the cluster.
Locks are placed on a resource grant or a convert queue, if the lock changes it moves between the queues. A lock leaves the convert queue under the following conditions
Convert requests are processed on a FIFO basis, the grant queue and convert queue are associated with each and every resource that is managed by the GES.
Enqueues are basically locks that support queuing mechanisms and that can be acquired in different modes. An enqueue can be held in exclusive mode by one process and others can hold a non-exclusive mode depending on the type. Enqueues are the same in RAC as they are in a single instance.
GES coordinates the requests of all global enqueues, it also deals with deadlocks and timeouts. There are two types of local locks, latches and enqueues, latches do not affect the cluster only the local instance, enqueues can affect both the cluster and the instance.
Enqueues are shared structures that serialize access to database resources, they support multiple modes and are held longer than latches, they protect persistent objects such as tables or library cache objects. Enqueues can use any of the following modes
Mode |
Summary |
Description |
NULL |
NULL |
no access rights, a lock is held at this level to indicate that a process is interested in a resource |
SS |
SubShared |
the resource can be read in an unprotected fashion other processes can read and write to the resource, the lock is also known as a row share lock |
SX |
Shared Exclusive |
the resource can be read and written to in an unprotected fashion, this is also known as a RX (row exclusive) lock |
S |
Shared |
a process cannot write to the resource but multiple processes can read it. This is the traditional share lock. |
SSX |
SubShared Exclusive |
Only one process can hold a lock at this level, this makes sure that only processes can modify it at a time. Other processes can perform unprotected reads. This is also know as a SRX (shared row exclusive) table lock. |
X |
Exclusive |
grants the holding process exclusive access to the resource, other processes cannot read or write to the resource. This is also the traditional exclusive lock. |
Each node has information for a set of resources, Oracle uses a hashing algorithm to determine which nodes hold the directory tree information for the resource. Global locks are mainly of two types
An instance owns a global lock that protects a resource (i.e. data block or data dictionary entry) when the resource enters the instance's SGA.
GES locks control access to data files (not the data blocks) and control files and also serialize interinstance communication. They also control library caches and the dictionary cache. Examples of this are DDL, DML enqueue table locks, transaction enqueues and DDL locks or dictionary locks. The SCN and mount lock are global locks.
Transaction and row locks are the same as in a single instance database, the only difference is that the enqueues are global enqueues, take a look in locking for an in depth view on how Oracle locking works.
The difference between RAC and a single instance messaging is that RAC uses the high speed interconnect and a single instance uses shared memory and semaphores, interrupts are used when one or more process want to use the processor in a multiple CPU architecture. GES uses messaging for interinstance communication, this is done by messages and asynchronous traps (ASTs). Both LMON and LMD use messages to communicate to other instances, the GRD is updated when locks are required. The messaging traffic can be viewed using the view V$GES_MISC.
A three-way lock message involves up to a maximum of three instances, Master instance (M), Holding instance (H) and the Requesting instance (R), the sequence is detailed below where requesting instance R is interested in block B1 from holding instance H. The resource is mastered in master instance M
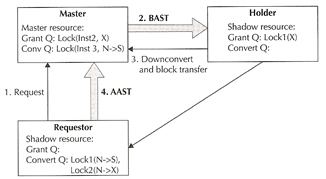 |
|
Because GES heavily rely's on messaging the interconnect must be of high quality (high performance , low latency), also the messages are kept small (128 bytes) to increase performance. The Traffic Controller (TRFC) is used to control the DLM traffic between the instances in the cluster, it uses buffering to accommodate large volumes of traffic. The TRFC keeps track of everything by using tickets (sequence numbers), there is a predefined pool of tickets this is dependent on the network send buffer size. A ticket is obtained before sending any messages, once sent the ticket is returned to the pool, LMS or LMD perform this. If there are no tickets then the message has to wait until a ticket is available. You can control the number of tickets and view them
| system parameter | _lm_tickets _lm_ticket_active_sendback (used for aggressive messaging) |
| ticket usage | select local_nid local, remote_nid remote, tckt_avail avail, tckt_limit limit, snd_q_len send_queue, tckt_wait waiting from v$ges_traffic_controller; |
| dump ticket information | SQL> oradebug setmypid Note: the output can be viewed here |
GCS locks only protect data blocks in the global cache (also know as PCM locks), it can be acquired in share or exclusive mode. Each lock element can have the lock role set to either local (same as single instance) or global. When in global role three lock modes are possible, shared, exclusive and null. In global role mode you can read or write to the data block only as directed by the master instance of that resource. The lock and state information is held in the SGA and is maintained by GCS, these are called lock elements. It also holds a chain of cache buffer chains that are covered by the corresponding lock elements. These can be view via v$lock_element, the parameter _db_block_hash_buckets controls the number of hash buffer chain buckets.
GCS locks uses the following modes as stated above
| Exclusive (X) | used during update or any DML operation, if another instance requires the block that has a exclusive lock it asks GES to request that he second instance disown the global lock |
| Shared (S) | used for select operations, reading of data does not require a instance to disown a global lock. |
| Null (N) | allows instances to keep a lock without any permission on the block(s). This mode is used so that locks need not be created and destroyed all the time, it just converts from one lock to another. |
Lock roles are used by Cache Fusion, it can be either local or global, the resource is local if the block is dirty only in the local cache, it is global if the block is dirty in a remote cache or in several remote caches. A Past Image (PI) is kept by the instance when a block is shipped to another instance, the role is then changed to a global role, thus the PI represents the state of a dirty buffer. A node must keep a PI until it receives notification from the master that a write to disk has completed covering that version, the node will then log a block written record (BWR). I have already discussed PI and BWR in my backup section.
When a new current block arrives, the previous PI remains untouched in case another node requires it. If there are a number of PI's that exist, they may or may not merge into a single PI, the master will determine this based on if the older PI's are required, a indeterminate number of PI's can exist.
In the local role only S and X modes are permitted, when requested by the master instance the holding instance serves a copy of the block to others. If the block is globally clean this instance lock role remains local. If the block is modified (dirty), a PI is retained and the lock becomes global. In the global lock role lock modes can be N, S and X, the block is global and it may even by dirty in any of the instances and the disk version may be obsolete. Interested parties can only modify the block using X mode, an instance cannot read from the disk as it may not be current, the holding instance can send copies to other instances when instructed by the master.
I have a complete detailed walkthough in my cache_fusion section, which will help you better to understand.
A lock element holds lock state information (converting, granting, etc). LEs are managed by the lock process to determine the mode of the locks, they also old a chain of cache buffers that are covered by the LE and allow the Oracle database to keep track of cache buffers that must be written to disk in a case a LE (mode) needs to be downgraded (X > N).
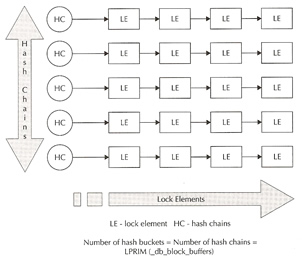
LEs protect all the data blocks in the buffer cache, the list below describes the classes of the data block which are managed by the LEs using GCS locks (x$bh.class).
| 0 | FREE |
| 1 | EXLCUR |
| 2 | SHRCUR |
| 3 | CR |
| 4 | READING |
| 5 | MRECOVERY |
| 6 | IRCOVERY |
| 7 | WRITING |
| 8 | PI |
So putting this altogether you get the following, GCS manages PCM locks in the GRD, PCM locks manage the data blocks in the global cache. Data blocks are can be kept in any of the instances buffer cache (which is global), if not found then it can be read from disk by the requesting instance. The GCS monitors and maintains the list and mode of the blocks in all the instances. Each instance will master a number of resources, but a resource can only be mastered by one instance. GCS ensures cache coherency by requiring that instances acquire a lock before modifying or reading a database block. GCS locks are not row-level locks, row-level locks are used in conjunction with PCM locks. GCS lock ensures that they block is accessed by one instances then row-level locks manage the blocks at the row-level. If a block is modified all Past Images (PI) are no longer current and new copies are required to obtained.
Consistent read processing means that readers never block writers, as the same in a single instance. One parameter that can help is _db_block_max_cr_dba which limits the number of CR copies per DBA on the buffer cache. If too many CR requests arrive for a particular buffer, the holder can disown the lock on the buffer and write the buffer to the disk, thus the requestor can then read it from disk, especially if the requested block has a older SCN and needs to reconstruct it (known as CR fabrication). This is technically known as fairness downconvert, and the parameter _fairness_threshold can used to configure it.
The lightwork rule is involved when CR construction involves too much work and no current block or PI block is available in the cache for block cleanouts. The below can be used to view the number of times a downconvert occurs
| downconvert | select cr_requests, light_works, data_requests, fairness_down_converts from v$cr_block_server; Note: lower the _fairness_threshold if the ratio goes above 40%, set to 0 if the instance is a query only instance. |
The GRD is a central repository for locks and resources, it is distributed across all nodes (not a single node), but only one instance masters a resource. The process of maintaining information about resources is called lock mastering or resource mastering. I spoke about lock remastering in my backup section.
Resource affinity allows the resource mastering of the frequently used resources on its local node, it uses dynamic resource mastering to move the location of the resource masters. Normally resource mastering only happens when a instance joins or leaves the RAC environment, as of Oracle 10g R2 mastering occurs at the object level which helps fine-grained object remastering. There are a number of parameters that can be used to dynamically remaster an object
| _gc_affinity_time | specifies interval minutes for remastering |
| _gc_affinity_limit | defines the number of times a instance access the resource before remastering, setting to 0 disable remastering |
| _gc_affinity_minimum | defines the minimum number of times a instance access the resource before remastering |
| _lm_file_affinity | disables dynamic remastering for the objects belonging to those files |
| _lm_dynamic_remastering | enable or disable remastering |
You should consult Oracle before changing any of the above parameters.
| Previous | Menu | Next |